Bonsoir,
Peut-être que je viens trop tard, peut-être que ce sera inutile. Mais voici un script que j’ai écrit qui permet de visualiser dans un terminal les changement opéré sur un etherpad. C’est écrit en Python, donc il faudra installer cet environnement auparavant d’exécuter le script. Je n’ai pas de Mac, donc je ne l’ai testé que sur mon portable sous Linux et sur une machine du boulot sous Windows 10 (DOS ou Powershell). Je ne garantis pas que cela fonctionne tout le temps. De plus cela dépend également de l’encodage du fichier Etherpad.
Enfin, si cela tente quelqu’un d’essayer. Il faut :
- Copier coller le script suivant dans un nouveau fichier que l’on nommera par exemple `EtherpadView.py´
- Ouvrir un terminal de commande selon son système d’exploitation (DOS, Powershell, Bash, etc… ), de préférence qui permet la colorisation du texte
- Copier le fichier etherpad dans le même dossier que ce script
- Exécuter la commande :
python EtherpadView.py my.pad (où my.pad est le nom du fichier pad copier au point 3)
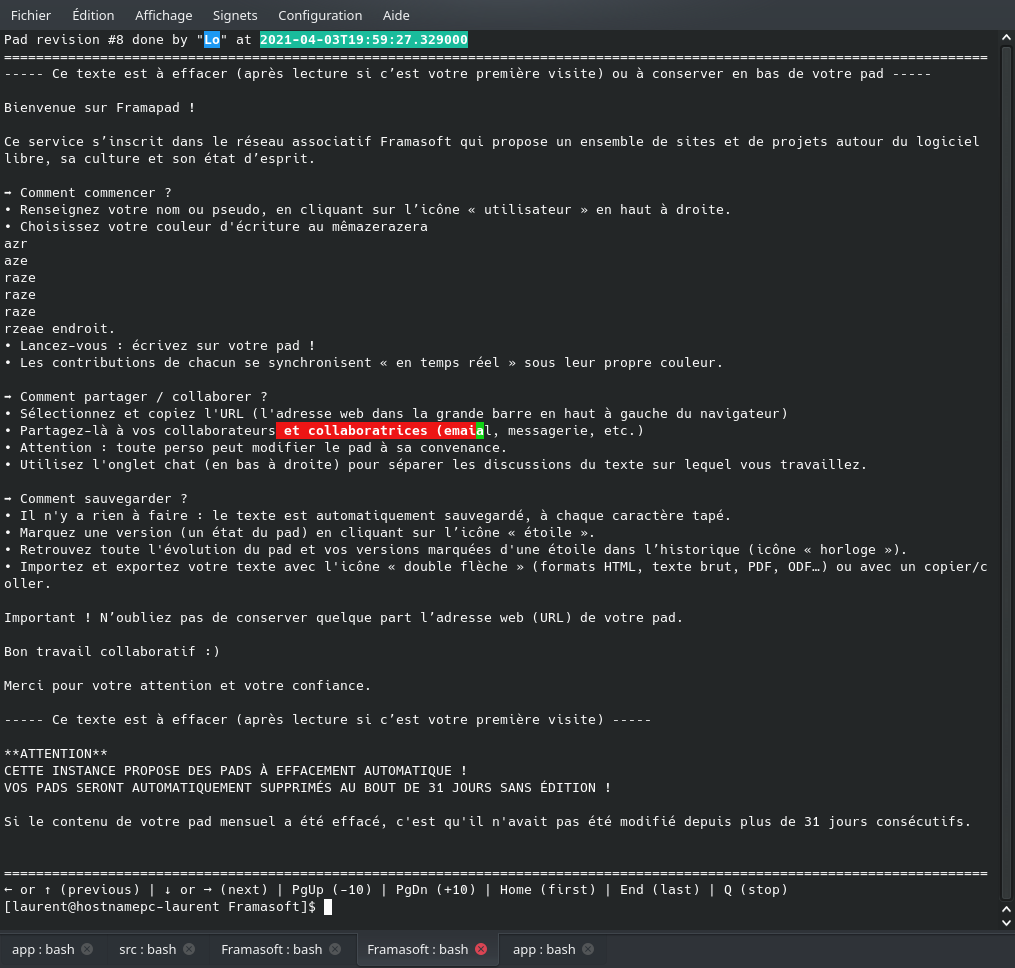
Cela affiche quelque chose comme ceci:
C’est en fait un peu comme l’historique de l’interface web le permet sur Framapad à la différence que cela montre également les éléments qui ont été supprimés.
On démarre à la version initiale. Et on navigue dans l’historique de la sorte:
- « flèche bas » ou « flèche droite » -> changement suivant
- « flèche haut » ou « flèche gauche » -> changement précédent
- « page haut » -> changement suivant par pas de 10
- « page bas » -> changement précédent par pas de 10
- « home » -> revenir à la version initiale
- « end » -> aller à la version finale
- « q » -> pour sortir
Pour l’affichage, on distinguera :
- en haut en bleu, le nom de la personne qui a fait les changements sur la version visualisée et en bleu-vert la date et l’heure à laquelle la modification a été faite
- dans le centre de la fenêtre, le texte. avec en vert les ajouts qui ont été faits, et en rouge les éléments qui ont étés supprimés.
Voici le script:
"""
EtherpadView helps viewing changes done on a Etherpad text.
Copyright (C) 2021 Pali Palo
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with this program. If not, see <https://www.gnu.org/licenses/>.
"""
from datetime import datetime
import json
import os
import sys
import shlex
import struct
import platform
import subprocess
# This code build a system dependent alias
# for clearing entire terminal screen
def get_clear():
current_os = platform.system()
if current_os == 'Windows':
return lambda: os.system('cls')
elif current_os in ['Linux', 'Darwin'] or current_os.startswith('CYGWIN'):
return lambda: os.system('clear')
else :
return lambda: os.system('cls')
clear = get_clear()
# The following code is used to get terminal attributes under Linux,
# Mac and Windows. (Hope this really works)
# This has been found here https://gist.github.com/jtriley/1108174
def get_terminal_size():
""" getTerminalSize()
- get width and height of console
- works on linux,os x,windows,cygwin(windows)
originally retrieved from:
http://stackoverflow.com/questions/566746/how-to-get-console-window-width-in-python
"""
current_os = platform.system()
tuple_xy = None
if current_os == 'Windows':
tuple_xy = _get_terminal_size_windows()
if tuple_xy is None:
tuple_xy = _get_terminal_size_tput()
# needed for window's python in cygwin's xterm!
if current_os in ['Linux', 'Darwin'] or current_os.startswith('CYGWIN'):
tuple_xy = _get_terminal_size_linux()
if tuple_xy is None:
tuple_xy = (80, 25) # default value
return tuple_xy
def _get_terminal_size_windows():
try:
from ctypes import windll, create_string_buffer
# stdin handle is -10
# stdout handle is -11
# stderr handle is -12
h = windll.kernel32.GetStdHandle(-12)
csbi = create_string_buffer(22)
res = windll.kernel32.GetConsoleScreenBufferInfo(h, csbi)
if res:
(bufx, bufy, curx, cury, wattr,
left, top, right, bottom,
maxx, maxy) = struct.unpack("hhhhHhhhhhh", csbi.raw)
sizex = right - left + 1
sizey = bottom - top + 1
return sizex, sizey
except:
pass
def _get_terminal_size_tput():
# get terminal width
# src: http://stackoverflow.com/questions/263890/how-do-i-find-the-width-height-of-a-terminal-window
try:
cols = int(subprocess.check_call(shlex.split('tput cols')))
rows = int(subprocess.check_call(shlex.split('tput lines')))
return (cols, rows)
except:
pass
def _get_terminal_size_linux():
def ioctl_GWINSZ(fd):
try:
import fcntl
import termios
cr = struct.unpack('hh',
fcntl.ioctl(fd, termios.TIOCGWINSZ, '1234'))
return cr
except:
pass
cr = ioctl_GWINSZ(0) or ioctl_GWINSZ(1) or ioctl_GWINSZ(2)
if not cr:
try:
fd = os.open(os.ctermid(), os.O_RDONLY)
cr = ioctl_GWINSZ(fd)
os.close(fd)
except:
pass
if not cr:
try:
cr = (os.environ['LINES'], os.environ['COLUMNS'])
except:
return None
return int(cr[1]), int(cr[0])
console_columns = get_terminal_size() [0]
# This code is used to get user input one char at a time
# without requesting the user to validate it with enter key
def _find_getch():
try:
import termios
except ImportError:
# Non-POSIX. Return msvcrt's (Windows') getch.
import msvcrt
return msvcrt.getch
# POSIX system. Create and return a getch that manipulates the tty.
import sys, tty
def _getch():
fd = sys.stdin.fileno()
old_settings = termios.tcgetattr(fd)
try:
tty.setraw(fd)
ch = sys.stdin.read(1)
finally:
termios.tcsetattr(fd, termios.TCSADRAIN, old_settings)
return ch
return _getch
getch = _find_getch()
# This code is used to decode base36 integer value found
# in the changeset.
# Base36 is a numeric system such this :
# 0, 1, 2, ..., 9, a, b, c, ..., z, 10, 11, .., 19, 1a, ...
def base36decode ( number ) :
return int ( number, 36 )
# This code is used to get the integer value for a command
# in a changeset
def get_changeset_value( changes_string, i ):
allowed_commands = ':><+-=|*'
value = ''
while i < len( changes_string ) and allowed_commands.find( changes_string[i] ) == -1 :
value += changes_string[i]
i += 1
return base36decode( value ), i
# This code is used to apply the changes on the previous
# version of the text, by following the commands found
# in the changset.
# Its output its a displayable text which have certain color;
# and the text modified accordingly to changeset. This allows
# caller to display a visual changes to the text and reroll
# the text for the next changeset.
def apply_pad_revision( revision_ID, text ) :
global revisions
tokens = revisions[ revision_ID ][ 'changeset' ].partition( '$' )
changes_string = tokens[0]
original_text = text
original_text_pos = 0
revision_text = tokens[2]
revision_text_pos = 0
modified_text = ''
modified_text_pos = 0
displayed_text = ''
displayed_text_pos = 0
i = 1 # 1 instead 0 to bypass leading Z char which is only a magic byte
while i < len( changes_string ) :
command = changes_string[i]
value, i = get_changeset_value( changes_string, i + 1 )
# print ( "Command : " + command + ' ' + str( value ) )
if command == ':' or command == '>' or command == '<' :
# ':' means previous revision text length
# '>' means number of char added to previous revision text
# '<' means number of char removed from previous revision text
# We do not need this information here, so pass it
pass
elif command == '+' :
# '+' means that X characters are to be added from this actual cursor
# within previous revision text.
modified_text += revision_text [ revision_text_pos : revision_text_pos + value ]
modified_text_pos += value
revision_text_part = revision_text [ revision_text_pos : revision_text_pos + value ]
if revision_text_part.endswith( '\n' ) :
revision_text_part = revision_text_part[ 0: len( revision_text_part ) - 1 ] + ' \n'
displayed_text += '\33[42;1m' + revision_text_part + '\33[0m'
displayed_text_pos += len( revision_text_part ) + len ( '\33[42;1m' + '\33[0m' )
revision_text_pos += value
# original_text_pos is unchanged since it is a new inserted text
elif command == '-' :
# modified_text_pos is unchanged
original_text_part = original_text [ original_text_pos : original_text_pos + value ]
if original_text_part.endswith( '\n' ) :
original_text_part = original_text_part[ 0: len( original_text_part ) - 1 ] + ' \n'
displayed_text += '\33[41;1m' + original_text_part + '\33[0m'
displayed_text_pos += len( original_text_part ) + len ( '\33[41;1m' + '\33[0m' )
original_text_pos += value
elif command == '=' :
modified_text += original_text [ original_text_pos : original_text_pos + value ]
modified_text_pos += value
displayed_text += original_text [ original_text_pos : original_text_pos + value ]
displayed_text_pos += value
original_text_pos += value
elif command == '|' :
sub_command = changes_string[i]
sub_value, i = get_changeset_value( changes_string, i + 1 )
# print( "Subcommand : " + sub_command + ' ' + str( sub_value ) )
if sub_command == '+' :
# '+' means that <sub_value> characters are to be added from this actual cursor
# within previous revision text and that added text contains <value> newline chars.
modified_text += revision_text [ revision_text_pos : revision_text_pos + sub_value ]
modified_text_pos += sub_value
revision_text_part = revision_text [ revision_text_pos : revision_text_pos + sub_value ]
if revision_text_part.endswith( '\n' ) :
revision_text_part = revision_text_part[ 0: len( revision_text_part ) - 1 ] + ' \n'
displayed_text += '\33[42;1m' + revision_text_part + '\33[0m'
displayed_text_pos += len( revision_text_part ) + len ( '\33[42;1m' + '\33[0m' )
revision_text_pos += sub_value
# original_text_pos is unchanged
elif sub_command == '-' :
# modified_text_pos is unchanged
original_text_part = original_text [ original_text_pos : original_text_pos + sub_value ]
if original_text_part.endswith( '\n' ) :
original_text_part = original_text_part[ 0: len( original_text_part ) - 1 ] + ' \n'
displayed_text += '\33[41;1m' + original_text_part + '\33[0m'
displayed_text_pos += len( original_text_part ) + len ( '\33[41;1m' + '\33[0m' )
original_text_pos += sub_value
elif sub_command == '=' :
modified_text += original_text [ original_text_pos : original_text_pos + sub_value ]
modified_text_pos += sub_value
displayed_text += original_text [ original_text_pos : original_text_pos + sub_value ]
displayed_text_pos += sub_value
original_text_pos += sub_value
elif command == '*' :
# Applying attributes to following changes. Generally this set
# the author of the change, but this in fact the same
# as the changeset author found in meta entry. So this is strictly
# ignored here. But this may reflect the font face or style change
# (bold, italic, color, etc.)
pass
displayed_text += original_text[ original_text_pos : ]
modified_text += original_text[ original_text_pos : ]
return displayed_text, modified_text
# This code is used to get response from the user depending on
# the system on wich this script runs.
def get_response() :
response = getch()
if platform.system() == 'Windows' :
response = hex( ord( response ) )
if response == '0xe0' :
sub_char = hex( ord( getch() ) )
if sub_char == '0x48' or sub_char == '0x4b' : # up or left
return 'prev'
elif sub_char == '0x50' or sub_char == '0x4d' : # down or right
return 'next'
elif sub_char == '0x48' : # home
return 'home'
elif sub_char == '0x46' : # end
return 'end'
elif sub_char == '0x49' :
return 'pgup'
elif sub_char == '0x51' :
return 'pgdn'
elif response == '0x71' : # lower byte of unicode value for q key
return 'q'
else :
if response == '\x1b' :
sub_char = getch()
if sub_char == '\x5b' :
sub_char = getch()
if sub_char == '\x41' or sub_char == '\x44' : # up or left
return 'prev'
elif sub_char == '\x42' or sub_char == '\x43' : # down or right
return 'next'
elif sub_char == '\x48' : # home
return 'home'
elif sub_char == '\x46' : # end
return 'end'
elif sub_char == '\x35' :
sub_char = getch()
if sub_char == '\x7e' : # page up
return 'pgup'
elif sub_char == '\x36' :
sub_char = getch()
if sub_char == '\x7e' : # page down
return 'pgdn'
return response
if __name__ == "__main__":
# handle sript parameter
if len( sys.argv ) != 2 :
print( "Please give one etherpad file name as argument for this script" )
quit()
# open the etherpad (which is indeed a json export of a variable)
with open( sys.argv[1] ) as json_file :
document = json.load(json_file)
# First, extract only revisions from Etherpad data.
# (In meantime, build the authors list to ease display later)
revisions = dict()
authors = dict()
for entry_ID in document :
tokens = entry_ID.split( ':' )
if entry_ID.startswith( 'pad:' ) :
# For all pad entries, # tokens[0] = "pad" and tokens[1] = pad ID.
# For revisionned pad entries, tokens[2] = "revs" and tokens[3] =
# revision sequential number
# (there might be several pads by design but not in this case)
if len( tokens ) == 4 and tokens[2] == 'revs' :
revisions[ tokens[3] ] = document[ entry_ID ]
if entry_ID.startswith( 'globalAuthor:' ) :
authors[ tokens[1] ] = document[ entry_ID ][ 'name' ]
# Then, parsed the revisions sorted by sequential revision number
# and change the text one step at a time.s
history = dict()
i = 0
text = '' # by default there is no text yet
for revision_ID in sorted( revisions, key=int ) :
title = ''
if revision_ID == '0' :
title = 'Pad revision #' + revision_ID + ' (original version)'
else :
revision_info = revisions[ revision_ID ][ 'meta' ]
author = '\33[44;1m' + authors[ revision_info[ 'author' ] ] + '\33[0m'
timestamp = '\33[46;1m' + datetime.fromtimestamp( revision_info[ 'timestamp' ] / 1000 ).isoformat() + '\33[0m'
title = 'Pad revision #' + revision_ID + ' done by "' + author + '" at ' + timestamp
displayed_text, text = apply_pad_revision( revision_ID, text )
sequence_information = dict()
sequence_information[ 'title' ] = title
sequence_information[ 'text' ] = displayed_text
history[ i ] = sequence_information
i += 1
# Finally navigate through change history (until user hit q key)
response = ''
history_sequence = 0
while response.lower() != 'q':
clear()
print( history[ history_sequence ][ 'title' ] )
print( "=" * int( console_columns ) )
print( history[ history_sequence ][ 'text' ] )
print( "=" * int( console_columns ) )
print( "← or ↑ (previous) | ↓ or → (next) | PgUp (-10) | PgDn (+10) | Home (first) | End (last) | Q (stop) ")
response = get_response()
if response == 'pgup' :
history_sequence -= 10
elif response == 'pgdn' :
history_sequence += 10
elif response == 'next' :
history_sequence += 1
elif response == 'prev' :
history_sequence -= 1
elif response == 'home' :
history_sequence = 0
elif response == 'end' :
history_sequence = len( history ) - 1
if history_sequence < 0 :
history_sequence = 0
elif history_sequence > len( history ) - 1 :
history_sequence = len( history ) - 1