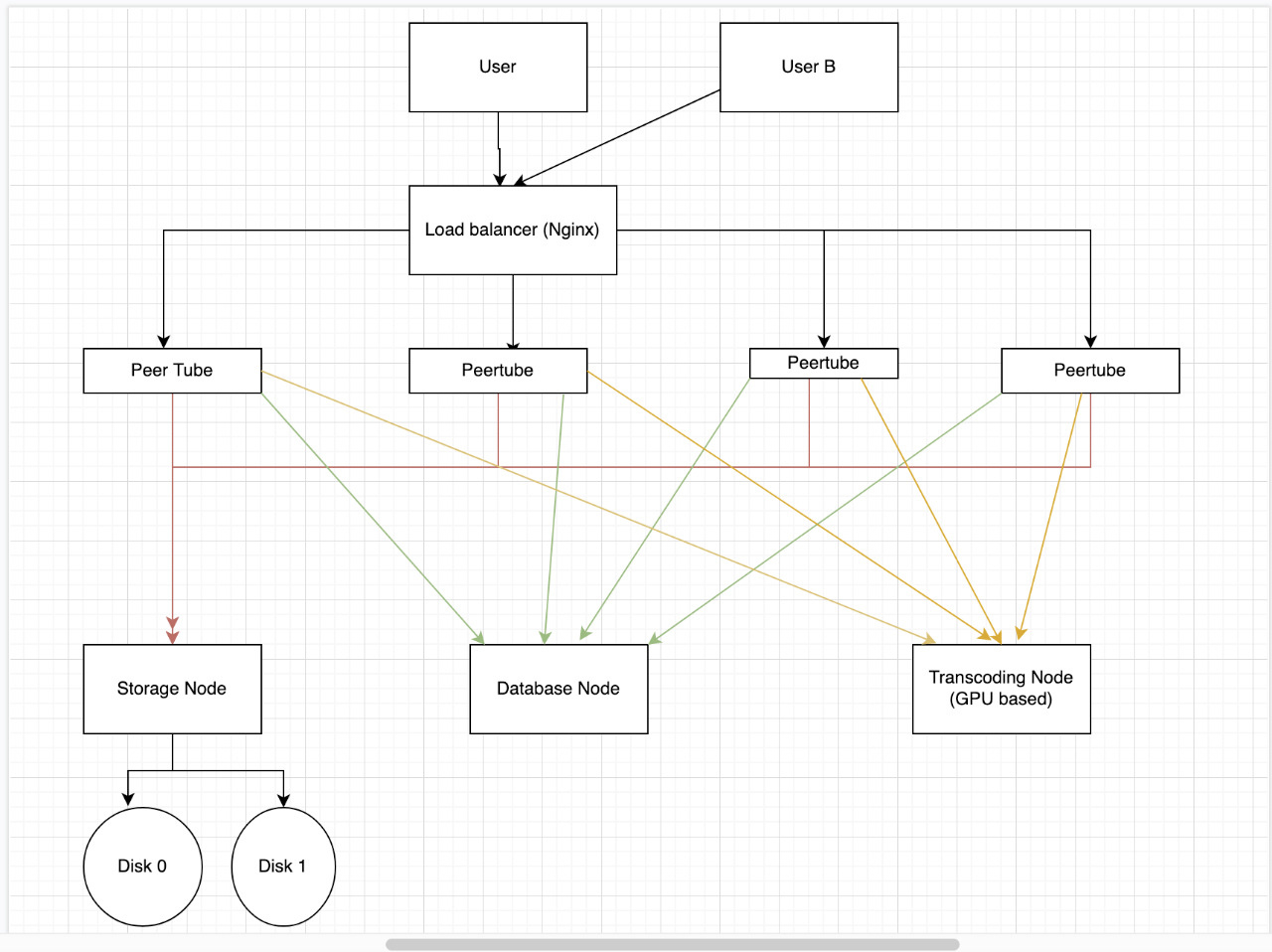
Hello I currently have like 20TB and as traffic is going more than GBPS the server is unable to scale so i would like to purchase another server and split the files so 10TB and another 10TB goes to server.
So at the end when user comes for different video they will be served from different server which will ultimately scale the traffic.
But I am seeing it as architectural issue atm.
I can run multiple peertube instance but I would like same design and only from 1 domain. I don’t need federation atm i want to run service like youtube do but for community .
I did came up with design that looks ok.
And I have tried RAID but i still cannot load balance it . Can somebody give me wisdom regarding this situation?
You’re hitting a hard problem: load-balancing write operations implies concurrency control, which we don’t have in PeerTube at the moment beyond local transactional control. This has more to do with how we interact with our database than how we designed PeerTube, but that means you cannot have multiple write operations from your multiple load-balanced instances writing to the database.
I see you are also assuming the transcoding makes use of GPU ressources. This is not the case either, as we don’t take advantage of GPU-enabling options in ffmpeg - mostly because I don’t have anything to test that on nor is it easy to detect.
Storage-wise however, there is a way to improve your situation, by following the S3 guide with a local minio instance. Since your main bottleneck is traffic, this allows you to offset traffic from a PeerTube instance and serve it from a single/clusterized minio.
I guess when u get popular this problem will arise eventually. And probably it is due to virus i am getting too much traffic. I wonder how other are handling it.
Thanks regarding database i guess its already super performant . The main bottleneck are storage and internet bandwidth. Any server usually don’t give more than 1GPBS connection. And Nginx always fail due to too much disk io.
As u said I think i should try s3 guide and see the result.
Thanks! Please reach out if you have trouble with it, and even if all is fine please tell us - we’ve had little feedback regarding if/how well this feature was deployed.
Just to mention it, several month ago I take a look on some parts of peertube’s code. There are other blocking problem that prevent this kind of architecture.
For example: the way it handles websocket connections and notifications. User list is kept in a global variable. The code was not writen so that the load can easily be divided between multiple process (or servers).
There can be many more example like this in the code, as it was not anticipated.
In the file server/lib/peertube-socket.ts, sockets are mapped to user ids this way: this.userNotificationSockets[userId].push(socket)
So, if there are multiple server, each server only knows users that are connected to itself. If there is a call to the sendNotification method, only users on the same server will be notified.
Moreover, if the load balancing is not consistent for a user (based on IP for example), and he has multiple browser tabs, there is no guaranty each tab will receive the notification.
This is one example of code that will not work if there are multiple web servers. I did not check other parts of the code, but if it was not designed to be distributed, there are probably many others blocking points.
Thanks! I have spotted others - mainly related to the job queue. If you don’t mind putting up a list, I could investigate if/how each can be alleviated.
I don’t have any free time right now, but if I see other points, I will report them here, or on the issue tracker.
Before trying to distribute peertube among multiple web servers, I think we could try to use an express cluster, so peertube can have multiple simultaneous process.
Note: for socket-io to work on multiple process (or servers), you must use redis-socket, and you have to load balance depending on IP, so that the socket.io handshake can work. But, when in dev mode, it is difficult to test with multiple IPs… In a project I made several month ago, I decided to have 2 distinct services: one for the web server, and one only for socket.io. So, I can only load balance the second one. If you want me to be more specific, just ask.
An other thing that is possible: distribute static files and/or duplicate them. In the case @shirshak55 is reporting, it is mainly a bandwidth problem. This could be probably solved this way.
Yes.
I use socketio-sticky-session for the sticky session, express-socket.io-session to share sessions between web servers and the notification server, and socket.io-redis to communicate between servers.
To sum up: my server.ts script use cluster.fork() to fork the web servers process, and the cluster.isMaster use fork() to launch a notifier.ts script, that is my socket.io server.
I’m a beginner on node/express, so I tried a lot of things. I tested more than 10 differents solutions. None of them were working (with this important goal in mind: be able to test multi process in dev mode with only one testing IP). So I decided to cut the service in two: web servers with real load balancing, without stick-session; a notification server which is less critical, and can do load balancing based on IP.